



Индексация страниц вашего сайта Google может быть полезной для повышения ее видимости в поисковой выдаче. Однако, иногда встает необходимость убрать определенные страницы или URL из индекса, чтобы не нарушать SEO-стратегию сайта или избежать дублирования контента. В этой статье мы рассмотрим 5 способов, которые помогут вам справиться с этой задачей.
Первым способом является использование robots.txt файла. Этот файл позволяет вам контролировать, какие страницы вашего сайта должны индексироваться поисковыми системами, а какие нет. Для того чтобы убрать URL из индекса Google, вы можете просто запретить индексацию этой страницы с помощью указания директивы «Disallow: /url» в файле robots.txt.
Третий способ — использование директивы «noindex» в файле robots.txt. В этом случае вы можете указать, что все страницы в определенной директории не должны индексироваться. Для этого вам нужно добавить следующую строку в файл robots.txt: Disallow: /your-directory/. Таким образом, все страницы в этой директории будут исключены из индекса Google.
Четвертым способом является использование тега «canonical». Этот тег позволяет указать, какая страница является оригиналом, если на сайте есть несколько страниц с одинаковым или схожим содержимым. Если вы хотите убрать URL из индекса Google, вы можете указать каноническую ссылку на другую страницу, которую вы хотите видеть в результатах поиска.
Последний, пятый способ — использование инструментов Google Search Console. В вашей учетной записи Google Search Console вы можете вручную запросить удаление URL из индекса. Для этого перейдите в раздел «Удаление URL» и следуйте инструкциям для запроса удаления страницы или директории из индекса Google. Этот способ особенно полезен, если вам необходимо быстро убрать URL из индекса поисковой системы.
Как убрать URL из индекса Google: 5 способов
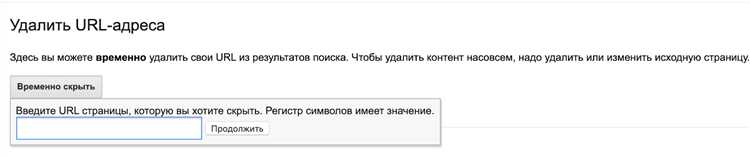

Иногда возникает необходимость убрать определенную страницу или URL из индекса Google. Например, если вы случайно опубликовали конфиденциальную информацию или если страница содержит устаревшую или нерелевантную информацию. В таких случаях можно воспользоваться следующими способами для удаления URL из индекса Google.
1. Использование файла robots.txt
Файл robots.txt является основным инструментом контроля, который используется поисковыми системами для определения того, какие страницы они могут индексировать. Вы можете добавить запрет на индексацию конкретного URL, добавив его в файл robots.txt. Например, вы можете добавить следующую строку: Disallow: /your-page-url/
2. Использование мета-тега noindex

Мета-тег noindex позволяет указать поисковым системам, что конкретная страница не должна быть проиндексирована. Для этого вам нужно вставить следующий код в раздел <head> страницы:
<meta name="robots" content="noindex"> <meta name="googlebot" content="noindex">
3. Использование отрицательного кода ответа на запрос страницы (404 или 410)
Если вы хотите удалить страницу из индекса Google, вы можете установить отрицательный код ответа на запрос страницы. Например, коды 404 и 410 указывают на то, что страница не найдена или удалена. Это заставит поисковую систему исключить страницу из индекса.
4. Удаление страницы через Google Search Console
Google Search Console предоставляет инструменты для управления вашим сайтом и включает функцию удаления URL из индекса. Вы можете воспользоваться этой функцией, чтобы быстро и эффективно удалить URL из индекса Google. Для этого вам нужно войти в свою учетную запись и выбрать соответствующую опцию в панели управления.
5. Установка «noindex» в файле sitemap.xml
Sitemap.xml представляет собой файл, который содержит список всех страниц вашего сайта, которые должны быть проиндексированы поисковиками. Вы можете использовать файл sitemap.xml, чтобы указать поисковым системам, какие страницы следует проиндексировать или исключить. Для исключения URL из индекса Google вам нужно добавить <meta name=»robots» content=»noindex»> перед каждым URL в файле sitemap.xml.
Использование robots.txt
Robots.txt — это текстовый файл, который размещается на корневом уровне сайта и содержит инструкции для поисковых роботов, указывая им, какие файлы и каталоги они могут обрабатывать. Этот файл является общепринятым соглашением между веб-мастерами и поисковыми системами, и его использование позволяет легко контролировать и управлять индексацией страниц.
Основные инструкции в файле robots.txt


Основные инструкции в файле robots.txt включают в себя:
- User-agent: — указывает на поискового робота, для которого задаются инструкции.
- Disallow: — указывает на файлы или каталоги, которые не должны быть индексированы.
- Allow: — указывает на файлы или каталоги, которые поисковые роботы могут обрабатывать, даже если они находятся в исключающем каталоге.
- Sitemap: — указывает на адрес карты сайта для облегчения индексации.
Таким образом, использование файла robots.txt позволяет более гибко настраивать индексацию сайта поисковыми системами, исключая нежелательные страницы и каталоги и улучшая видимость и рейтинг вашего сайта в поисковой выдаче.
Использование мета-тега noindex
Мета-тег noindex позволяет указать поисковым системам, что страница не должна быть индексирована. Это может быть полезно, когда вы не хотите, чтобы ваша страница появлялась в результатах поиска Google. Мета-тег noindex может быть добавлен в HTML-код каждой страницы вашего сайта.
Чтобы использовать мета-тег noindex, откройте HTML-файл вашей страницы в текстовом редакторе и добавьте следующий код в секцию <head>:
<meta name="robots" content="noindex">
Мета-тег noindex указывает поисковым системам, что страница не должна быть индексирована. Это может быть полезно, когда вы создаете временную или административную страницу, которая не предназначена для показа в результатах поиска Google. Используя мета-тег noindex, вы можете управлять тем, как поисковые системы обрабатывают определенные страницы вашего сайта.
Пример использования мета-тега noindex
Пример 1: Если вы хотите, чтобы конкретная страница вашего сайта была исключена из индекса Google, вставьте следующий код в HTML-файл страницы:
<meta name="robots" content="noindex">
Пример 2: Если вы хотите, чтобы все страницы внутри определенной папки были исключены из индекса Google, добавьте создайте файл robots.txt в корневой папке вашего сайта и добавьте следующий код:
User-agent: * Disallow: /folder/
В приведенном выше примере, все страницы, находящиеся внутри папки «folder», не будут индексироваться Google.
Использование Google Search Console
Один из основных функциональных блоков Google Search Console – это инструменты для управления сайтом, такие как инструкции по устранению ошибок, анализ показателей производительности сайта, оптимизация содержимого для поисковых систем и др. В Google Search Console также можно получить доступ к отчетам о состоянии индексации страниц сайта, информации о запрещении индексации, структурированных данных, ссылках на ваш сайт, а также аналитике пользовательского опыта и показателях скорости загрузки сайта.
Преимущества использования Google Search Console:
- Отслеживание состояния индексации сайта – с помощью инструментов Google Search Console вы всегда можете быть в курсе, сколько страниц вашего сайта проиндексировано в Google и как они отображаются в поисковой выдаче. Вы также можете контролировать процесс индексации новых страниц и управлять проблемами, которые могут влиять на видимость сайта.
- Выявление ошибок и проблем на сайте – Google Search Console предоставляет детальные отчеты о наличии ошибок на вашем сайте, таких как «страница не найдена» или «ошибка сервера». Это позволяет вам оперативно реагировать на такие проблемы и улучшать пользовательский опыт на вашем сайте.
- Оптимизация содержимого для поисковых систем – Google Search Console предоставляет данные о запросах, по которым пользователи находят ваш сайт, а также показывает, на каких позициях в поисковой выдаче располагаются ваши страницы. Это помогает вам оптимизировать содержимое своего сайта, чтобы привлечь больше органического трафика.
Использование Google Search Console является важной частью SEO-оптимизации вашего сайта. Этот инструмент позволяет вам контролировать видимость и состояние вашего сайта в поисковой выдаче Google, а также выявлять и исправлять ошибки, что помогает повысить его рейтинг и привлечь больше посетителей.
Удаление страницы с помощью файла XML Sitemap
Чтобы удалить страницу с помощью файла XML Sitemap, вам необходимо выполнить следующие шаги:
- Создайте XML Sitemap. Для этого вы можете воспользоваться специальными онлайн-сервисами или использовать генераторы Sitemap, которые автоматически создадут файл на основе структуры вашего сайта.
- Добавьте ссылку на страницу, которую вы хотите удалить, в файл XML Sitemap. Для этого вам нужно просто добавить соответствующую строку с URL страницы в формате <url><loc>http://www.example.com/страница</loc></url>.
- Сохраните файл XML Sitemap и загрузите его на ваш сервер. Убедитесь, что файл доступен для поисковых систем по запросу. Для проверки вы можете ввести URL файла в адресную строку браузера и убедиться, что он отображается корректно.
- Отправьте файл XML Sitemap в Google Search Console. Для этого вам нужно войти в свою учетную запись Google Search Console, выбрать нужный сайт и перейти в раздел «Sitemaps». Затем нажмите на кнопку «Добавить/тестировать Sitemap» и укажите URL вашего файла XML Sitemap. Нажмите «Отправить» и подтвердите действие.
- Подождите, пока Google проиндексирует ваш файл XML Sitemap и обработает изменения. Обычно это занимает некоторое время, поэтому будьте терпеливы.
После выполнения всех этих шагов страница, указанная в файле XML Sitemap, должна быть исключена из индекса Google. Однако стоит учесть, что это не является гарантированным способом удаления страницы из поисковой выдачи. Google может сохранять копии страниц, кэшированные версии или ссылки на нее через другие источники. Поэтому, чтобы быть уверенным в полном удалении страницы из индекса, рекомендуется использовать комбинацию различных методов и инструментов SEO.
Использование команды «нераспознаваемость» в robots.txt файле
Команда «нераспознаваемость» в файле robots.txt позволяет указать поисковым роботам, что они не должны индексировать определенную часть вашего сайта. Это может быть полезно, если вам необходимо скрыть конкретные URL от поисковых систем, например, чтобы защитить конфиденциальные данные или временно скрыть страницы в процессе изменений.
Чтобы использовать команду «нераспознаваемость», вам необходимо добавить соответствующую строку в файл robots.txt вашего сайта. Например, если вы хотите скрыть страницу с URL «http://www.example.com/hidden-page.html», вы можете добавить следующую строку:
Disallow: /hidden-page.html
Это указывает поисковым роботам не индексировать страницу с URL «http://www.example.com/hidden-page.html». При этом, важно отметить, что эта команда не гарантирует полную нераспознаваемость страницы, так как поисковые роботы могут проигнорировать указания файла robots.txt и продолжить индексировать страницу.
Использование команды «нераспознаваемость» может быть полезным инструментом для SEO-оптимизации вашего сайта. Однако, перед тем как использовать эту команду, необходимо внимательно продумать и проанализировать, какие страницы или разделы сайта вы действительно хотите скрыть от поисковых систем, чтобы не нанести ущерба видимости и рейтингу вашего сайта в поисковой выдаче.
Итак, команда «нераспознаваемость» в robots.txt файле является одним из способов управления процессом индексации поисковыми системами. Это мощный инструмент, который позволяет вам контролировать, какие страницы вашего сайта будут видимы в поисковых результатах, а какие будут скрыты. Однако, не забывайте, что эта команда не гарантирует полную нераспознаваемость страницы, и поисковые роботы могут проигнорировать её. Поэтому, перед применением команды «нераспознаваемость», важно тщательно обдумать свои действия и учитывать последствия для SEO-оптимизации вашего сайта.