



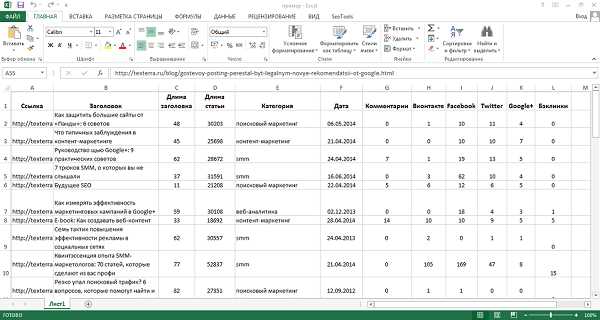
В предыдущей статье мы рассмотрели, что такое анализ контента и как он может быть полезен при разработке веб-сайтов. В этой статье мы поговорим о втором этапе анализа контента — обработке данных.
Обработка данных — это процесс преобразования сырых данных, полученных на первом этапе анализа контента, в более удобный и структурированный формат. Данные могут быть представлены в различных форматах: текстовые файлы, таблицы Excel, базы данных и т. д. Основная цель обработки данных — сделать их более доступными для последующего анализа и использования.
Для обработки данных часто используются специальные программы и инструменты. Например, веб-скрейпинг позволяет автоматически собирать данные со страниц веб-сайтов, а SQL-запросы используются для извлечения нужной информации из базы данных. Также для обработки данных можно использовать языки программирования, такие как Python или R, которые обладают мощными возможностями в области работы с данными.
В этой статье мы рассмотрим различные методы обработки данных, такие как фильтрация, преобразование и агрегация. Также мы рассмотрим примеры использования специальных инструментов и программ для обработки данных.
Анализ контента. Часть 2. Обработка данных
Вторая часть анализа контента посвящена обработке данных. На этом этапе необходимо выполнить ряд задач, включая очистку данных от лишних символов и пропусков, нормализацию текста, удаление стоп-слов, проведение лемматизации и токенизации.
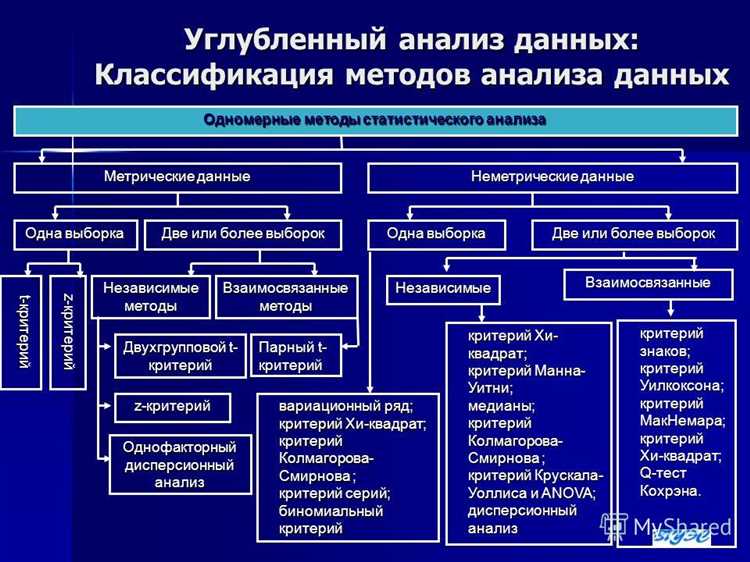
Одним из методов обработки данных является применение частотного анализа. На данном этапе происходит подсчет частоты встречаемости слов в тексте. Это позволяет выделить наиболее часто встречающиеся слова и определить их значимость для данного контекста. Для визуализации полученных результатов можно использовать графики и диаграммы.
- Подготовка и структурирование данных
- Очистка данных
- Нормализация текста
- Удаление стоп-слов
- Лемматизация и токенизация
- Частотный анализ
В результате проведения обработки данных можно получить ценную информацию о контенте, такую как ключевые слова, наиболее часто встречающиеся словосочетания, темы и смысловые связи между текстами. Эта информация может быть использована для определения направления контента, повышения его качества и привлечения большего количества читателей и пользователей.
Основные понятия обработки данных

Одним из основных понятий в обработке данных является понятие данных. Данные – это факты или информация, которая записывается и хранится в компьютерной системе. Они могут быть представлены в различных форматах, таких как числа, текст или графические изображения.
- Сортировка данных – процесс упорядочивания данных по определенным критериям. Это может быть сортировка по возрастанию или убыванию чисел, или же по алфавиту для текстовых данных.
- Фильтрация данных – процесс выбора определенных данных из общей массы на основе заданных условий или критериев. Это позволяет исключить ненужные данные и сосредоточиться только на тех, которые необходимы для анализа.
- Агрегация данных – процесс объединения нескольких данных в одно целое. Например, агрегация может использоваться для составления общего отчета по продажам, путем суммирования данных из различных источников.
- Структурирование данных – процесс организации данных в определенный формат или структуру. Например, данные могут быть организованы в виде таблицы, графа или дерева, чтобы облегчить их понимание и анализ.
Все эти операции обработки данных помогают превратить сырые данные в информацию, которая может быть легко воспринята и использована для принятия решений. Обработка данных играет ключевую роль в различных областях, таких как бизнес, наука, медицина и технологии.
Автоматизированный сбор данных
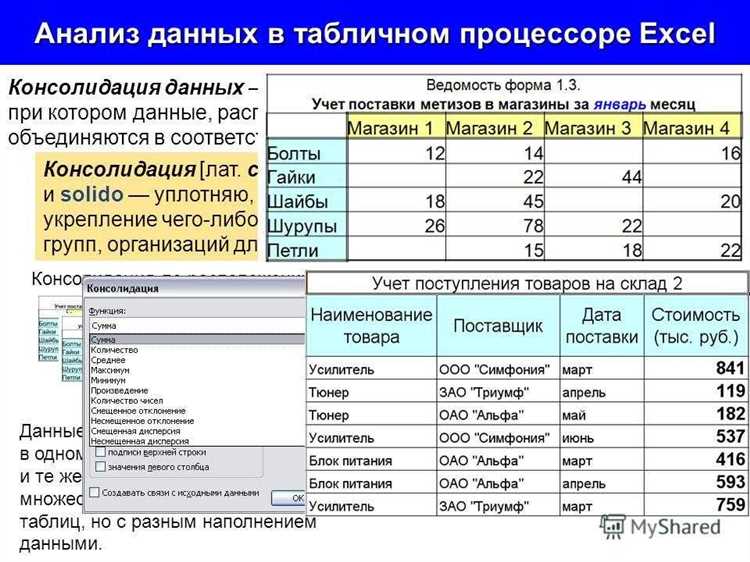

Автоматизированный сбор данных осуществляется с помощью специального программного обеспечения, такого как веб-скрейперы или боты. Эти программы могут просматривать веб-страницы, извлекать нужные данные, сохранять их и даже анализировать. Такой подход значительно упрощает и ускоряет процесс сбора информации и позволяет сосредоточиться на анализе полученных данных.
Преимущества автоматизированного сбора данных:
- Экономия времени и ресурсов. Вместо того чтобы вручную собирать информацию, автоматизация позволяет получить нужные данные в автоматическом режиме.
- Повышение точности и надежности. Вручную собранные данные могут содержать ошибки и неточности, в то время как автоматизированный сбор данных позволяет получить более точные и надежные результаты.
- Широкий охват. Автоматизированный сбор данных позволяет обработать большой объем информации, что может быть сложно или невозможно вручную.
Однако, при использовании автоматизированного сбора данных необходимо соблюдать законы и этические нормы. Важно убедиться, что сбор данных происходит с согласия владельцев информации и не нарушает их права на конфиденциальность и безопасность.
Очистка и предобработка данных
В ходе очистки данных применяются различные методы и алгоритмы. Один из основных этапов – это обнаружение и удаление выбросов. Выбросы – это данные, которые значительно отличаются от общей тенденции и могут являться ошибочными или аномальными. Их удаление позволяет улучшить качество данных и повысить точность анализа. Еще одним важным шагом в процессе очистки данных является заполнение пропущенных значений. Пропуски данных могут быть вызваны ошибками ввода, отсутствием информации или другими причинами. Заполнение пропусков позволяет сохранить данные и не потерять информацию при дальнейшем анализе.
Примеры методов очистки и предобработки данных:
- Удаление дубликатов;
- Замена неточных значений;
- Удаление лишних символов;
- Приведение данных к нужному формату;
- Агрегация и группировка данных;
- Удаление несущественных переменных;
- Нормализация данных;
- Стандартизация данных.
Очистка и предобработка данных – это важный этап перед проведением анализа контента. Качество и правильность результатов анализа напрямую зависят от того, насколько хорошо данные были очищены и предобработаны. Правильные методы очистки и предобработки позволяют получить более достоверные и точные результаты, а также упрощают и ускоряют процесс анализа.
Анализ и визуализация данных

Визуализация данных – это метод представления информации в графическом или диаграмматическом виде, который делает данные более понятными и наглядными. Визуализация данных позволяет обнаруживать закономерности, выявлять тренды, сравнивать значения и анализировать различные аспекты информации. Благодаря визуализации, сложные и объемные данные могут быть представлены в удобной и интуитивно понятной форме.
Преимущества анализа и визуализации данных:
- Более глубокое понимание данных и информации;
- Выявление скрытых или незаметных закономерностей и зависимостей;
- Предоставление четкой и наглядной информации для принятия решений;
- Улучшение коммуникации и обмена информацией;
- Обнаружение аномалий и выбросов в данных;
- Упрощение и ускорение процесса анализа данных;
- Повышение эффективности и результативности в различных областях деятельности.
В итоге, анализ и визуализация данных являются мощными инструментами для получения ценной информации, принятия решений и разработки стратегий в различных сферах – от бизнеса до науки.
Применение алгоритмов машинного обучения
Алгоритмы машинного обучения имеют широкое применение в различных областях, включая анализ контента. Они могут использоваться для обработки и классификации данных, автоматической категоризации контента, прогнозирования трендов и многое другое. Применение алгоритмов машинного обучения позволяет автоматизировать процессы анализа данных и повысить точность и эффективность получаемых результатов.
В области анализа контента алгоритмы машинного обучения могут использоваться для:
- Автоматического извлечения ключевых слов и фраз из текстового содержимого;
- Анализа тональности текстов и определения эмоционального окраса;
- Классификации контента по тематике, стилю или другим характеристикам;
- Автоматического создания резюме или краткой выжимки из большого объема текста;
- Прогнозирования трендов и предсказания изменений в контенте в будущем.
Однако, необходимо помнить, что успешное применение алгоритмов машинного обучения требует качественных данных для обучения и подготовки модели. Также важно выбрать подходящий алгоритм и параметры модели для конкретной задачи анализа контента.
В итоге, применение алгоритмов машинного обучения в анализе контента может значительно упростить и ускорить процессы обработки данных, а также повысить качество получаемых результатов. Они помогают автоматизировать задачи, которые ранее требовали большого количества времени и усилий. В будущем, с развитием технологий и улучшением алгоритмов, анализ контента при помощи машинного обучения будет становиться все более точным и эффективным инструментом для работы с данными.